Parallel Computation
Flynn’s taxonomy
| Single Data stream | Multiple Data stream | |
|---|---|---|
| Single Instruction | SISD: “Regular” processor | SIMD: Vectorisation |
| Single Data | MISD: Uncommon - n-version programming | MIMD: Distributed systems |
More detail below.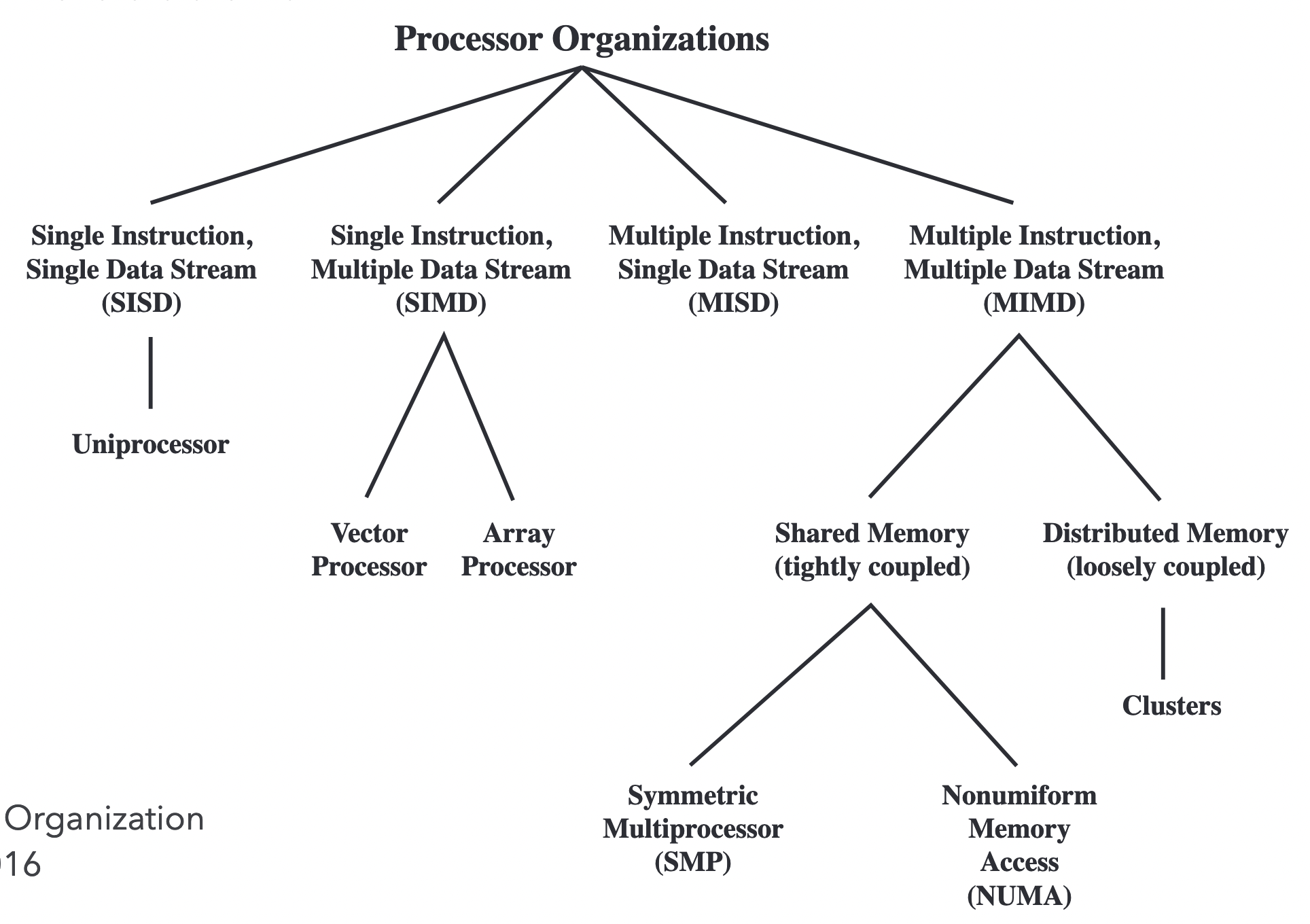
Flynn's taxonomy
MIMD
- Available as shared memory and distributed memory.
- Shared memory: Communicate via memory, easy to program.
- Distributed memory: Communication can be done between autonomous processors in software. Examples include Ethernet, Infiniband, etc. Communicates via message passing.
- Hardware interconnection structures allow processors to access memory and communicate with other processors.
Hardware interconnection
- Shared bus: Limited bandwidth, single point of failure, hard to resolve contention for resource.
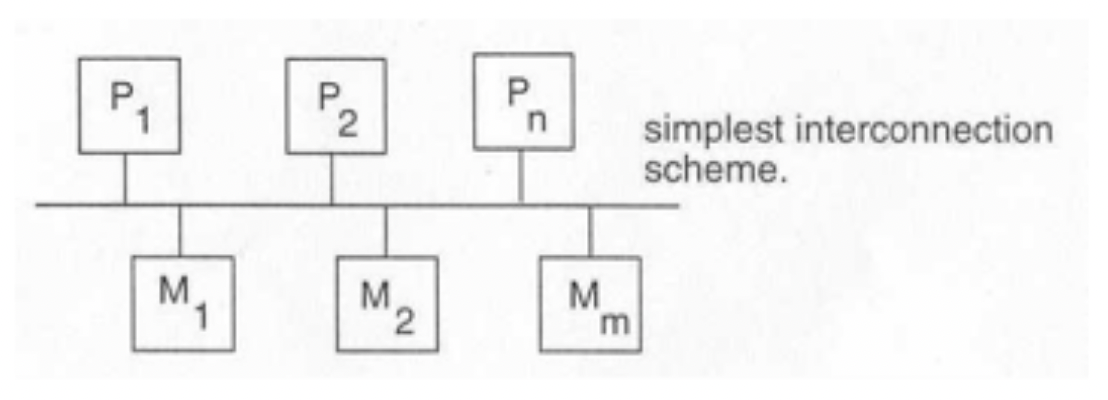
Shared Bus
- Cross bar switch matrix: High bandwidth, good reliability, but still contention for same memory. Physically large and costly.
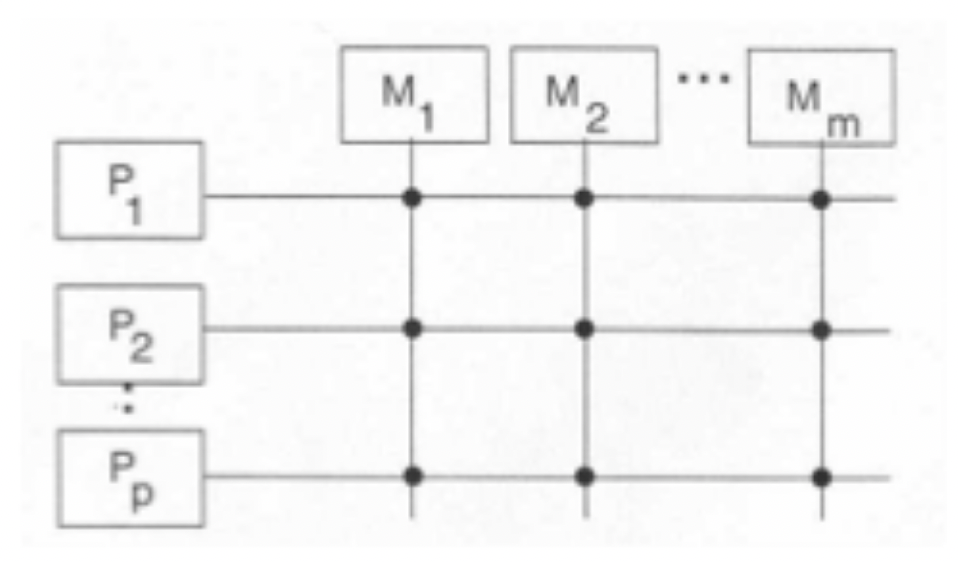
Cross bar switch matrix
- Static (dedicated links): the more links, the greater the interprocessor communication rate.
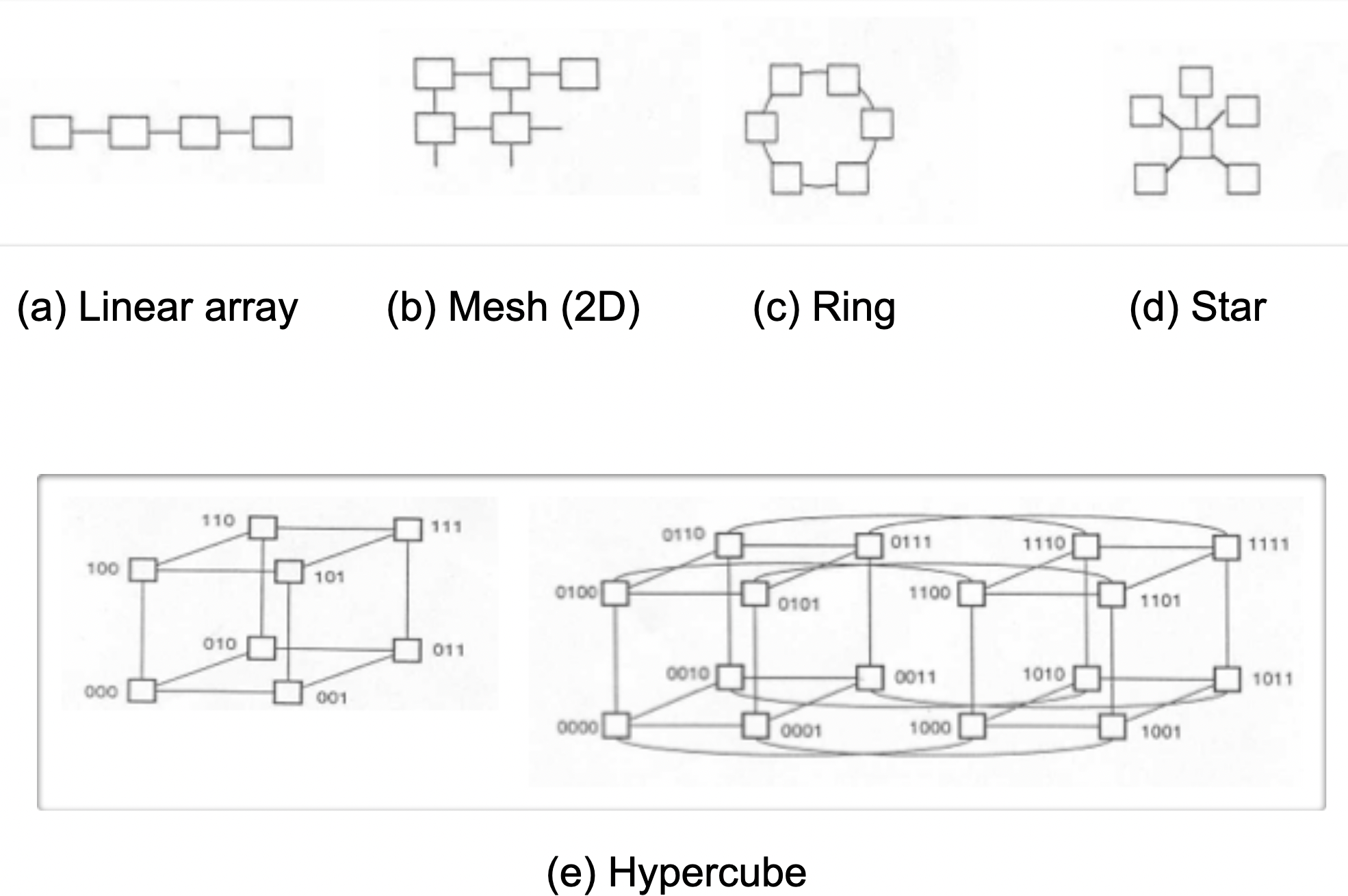
Static structures
| Structure | # of connections | # links per node | Max internode distance |
|---|---|---|---|
| Linear array | $$n-1$$ | $$2$$ | $$n-1$$ |
| Mesh: size $$\sqrt{n}\times\sqrt{n}$$ | $$2(n-\sqrt{n})$$ | $$4$$ | $$2(\sqrt{n}-1)$$ |
| Ring | $$n$$ | $$2$$ | $$\frac{n}{2}$$ |
| Star | $$n-1$$ | $$n-1$$ | $$2$$ |
| Hypercube: size $$n=2^k$$ | $$\frac{n}{2}\log_{2}{n}$$ | $$\log_{2}{n}$$ | $$\log_{2}{n}$$ |
| Complete connection | $$\frac{n(n-1)}{2}$$ | $$n-1$$ | $$1$$ |
- Multistage switching networks: ALl processors connected to all other processors, and all requests non blocking. CLOS (Multistage cross bar switches) were originally made for telephone exchanges.
- Uses 3 or more ‘stages’, where processor in a stage are connected to all others in the preceeding and succeeding stages. Non blocking and smaller than a cross bar switch matrix.
- 2 elements in each stage is a Benes network
- Cell based networks: single bit control for data path i.e. each cell has 2 connections. Can be highly blocking, but needs fewer switches.
- Baseline: uses ‘self-routing’, take one path for 0, one path for 1 (see below).
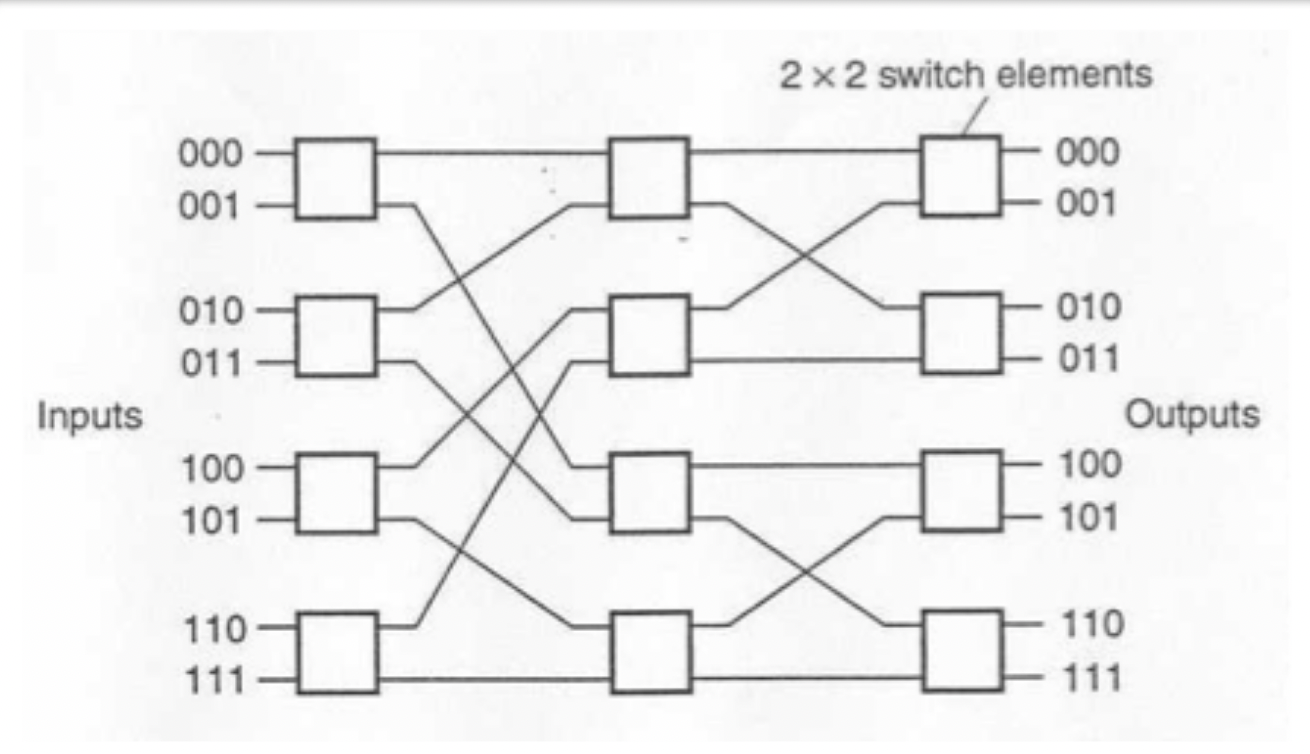
Baseline Network
Cache coherence
In MIMD shared memory systems, we need to keep cache coherency over all autonomous processors. There are many ways to solve this:
- Shared caches: this has poor performance.
- Non-cachable items: can cause problems!
- Broadcast write: All cache writes are also sent to other caches. Copies in other caches are updated (slower) or invalidated (faster, but requires a fetch if needed by other processor).
- Snoop bus: Write through, bus watcher checks for main memory writes on bus. If so, it invalidates it’s local copy of the data written.
- Directory methods: Lists of cached copies of data.
- Full directory: Pointer bit for each processor, + dirty bit. Pointer set if that processor has a copy. Valid bit and private bit with data in cache - valid if data is up to date, private set if processor can write to it.
- Limited directory: Only a fixed number of processors can have a copy of a piece of data. Directory therefore smaller.
- Chained directory: Linked lists hold dictionary entries. Every entry in a cache points to another copy somewhere else.
- MESI protocol: Snoop bus with write back policy instead. Each cache line can be in 1 of 4 states:
- Modified: Cache entry valid, main memory copy invalid, no copies exist.
- Exclusive: No other cache holds the data, main memory up to date.
- Shared: Other caches also hold the data, main memory up to date.
- Invalid: Cache data invalid.
- All cache lines start as invalid. When one fetches, it sets exclusive. When another fetches the same, it knows another cache has a copy from snooping, so sets shared, and so does the first cache.
- Before a cache is written to, an invalidate signal is put on the bus, telling other caches to mark their copy invalid.
- Exclusive correct copy is only written back to main memory when another CPU requests that data.
- On a cache miss, Read with intent to modify (RWITM) routine happens - owner of the data writes it to memory.
Data level parallelism
SIMD variations:
Vector architecture
- Easy to compile for, reduces fetch bandwidth needed since less instructions to fetch.
- Vector units are pipelined, scalar registers used to compute addresses to pass to vector unit.
- Specialised vector load / store unit used to load to and from vector units.
3 factors contribute to vector execution time: Length of vector operand, structural hazards and data dependency.
- Convoys: set of vector instructions that can potentially execute together. Number of convoys a good measure of performance.
- Chaining: Vector operation can start as soon as elements of vector source become available.
- Chime: unit of time to execute a single convoy.
Vector architecture optimisation techniques:
- Multiple lanes: i.e. pipelining combined operations
- Vector length registers: lets us optimise sections with less data than max. vector length (MVL)
- Mask registers: Provides conditional execution for each vector element
- Memory banking: to speed up vector initiation rate
GPUs
- GPU parallelism unified as CUDA thread
- CUDA threads organised into blocks of up to 512, whole blocks get executed at once
Multithreading
- MIPS = frequency (MHz) * Instructions per second.
- Instruction stream divided so threads can execute in parallel.
- Explicit multithreading: Interleaving explicitly different threads into the same pipeline / on parallel pipelines.
- Implicit multithreading: Extracting multiple threads from the same program.
- Interleaved/fine grain: Switch between each thread each cycle.
- Block/coarse grain: Only switch when one thread causes a delay.
- Simultaneous multithreading: using multiple execution units.
- Chip multiprocessing: each core handles a thread.
Multicore
- Cores may or may not share different levels of cache .
- Shared cache advantages: Constructive inference can reduce miss rates, Data shared by cores need not be replicated, can dynamically allocate cache space to each thread, interprocessor communication easy with shared memory, Cache coherence problem reduced.
Clusters
- Group of ’node’ computers pretending to be one computer.
- Uniform memory acces (UMA): All processors can access all parts of memory, and at the same rates.
- Non-UMA (NUMA): All processors can access all parts of memory, but some processsors can access some patrts of memory faster / slower than others
- Clusters scale very well.
- Cache coherent NUMA (CC-NUMA): Maintains a transparant system wide memory whilst permitting individual nodes, usually using a directory method.
Thread level parallelism:
- Instruction pairing: Link 2 instructions, get a result telling you if there was a context switch between their execution.
- Gives safety to fetch and increment instructions eg. x+=1.
- Memory consistency: If write invalidates are delayed, branches relying on values processed in other threads may be incorrect. We need sequential consistency.
- Sequential consistency can hurt performance; we can use latency hiding techniques and relaxed consistency models to help this.
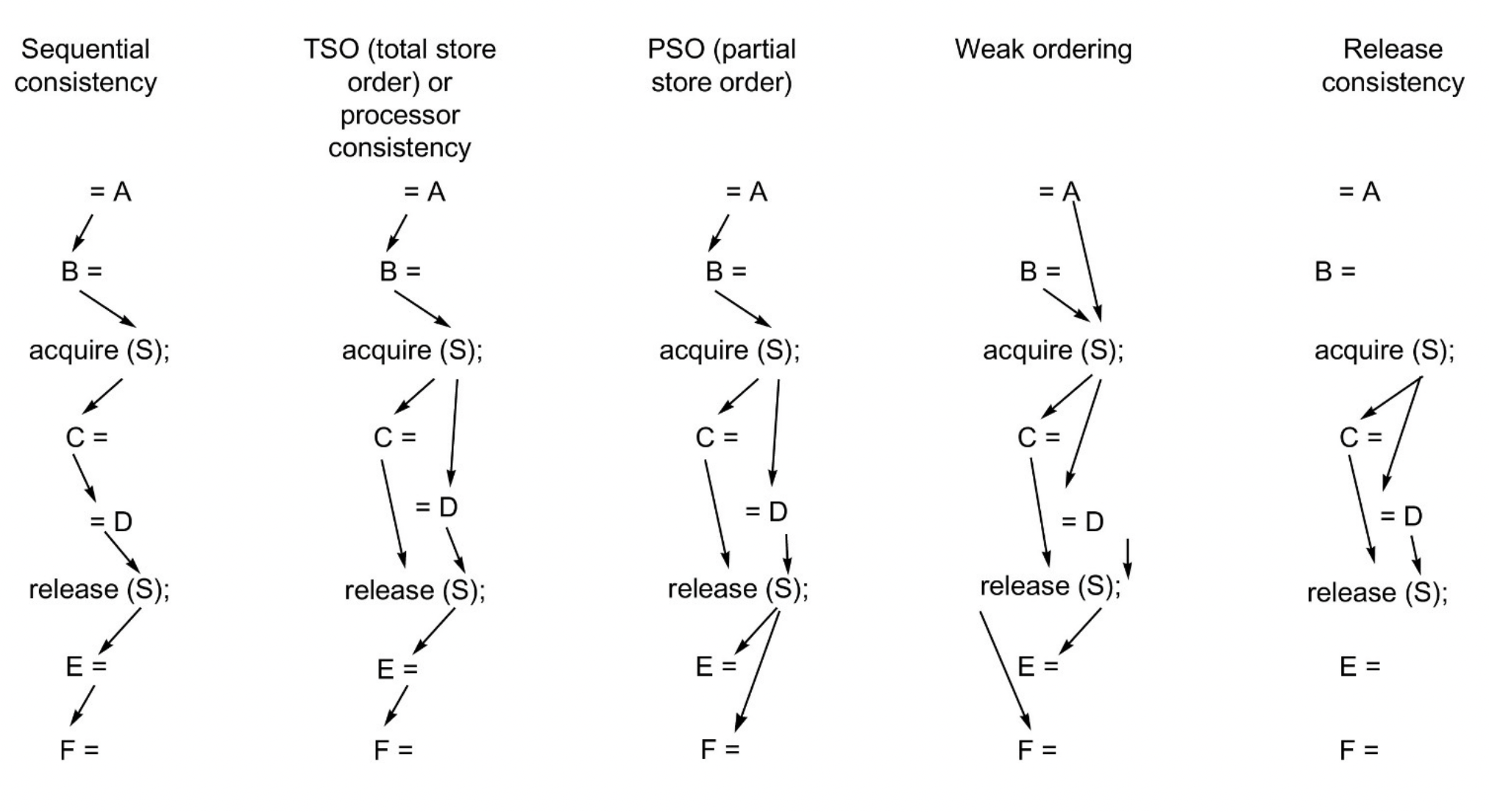
Relaxed consistency models
A -> B denotes A must be completed before B. We have 4 sets of constraints we can relax:
- W->R: Total store ordering model, retains ordering of writes.
- W->W: Partial order store model - impractical for most programs.
- R->R and R/W: Variety of models incl. weak ordering and release consistency, depending on how synchronisation enforces orderings.